
Synopsis
We learned a lot on how to best manage Claude Code's context window (and our own limited human cognitive context window) and what it means for building AI-native software in the past few months. This lightning talk distills those insights and protips: multiple parallel Claude coding sessions, special hardware tricks, ways to bring the most relevant context to your agents, and advice to design your feedback loop. All in 5 minutes.
Audience
Developers building with LLMs, indie hackers and startup founders shipping AI tools, advanced technical profiles actively building with Claude.
Slides





Key Takeaways
This lightning talk shares practical insights from building AlexandrIA with Claude Code over the past few months. Three themes covered:
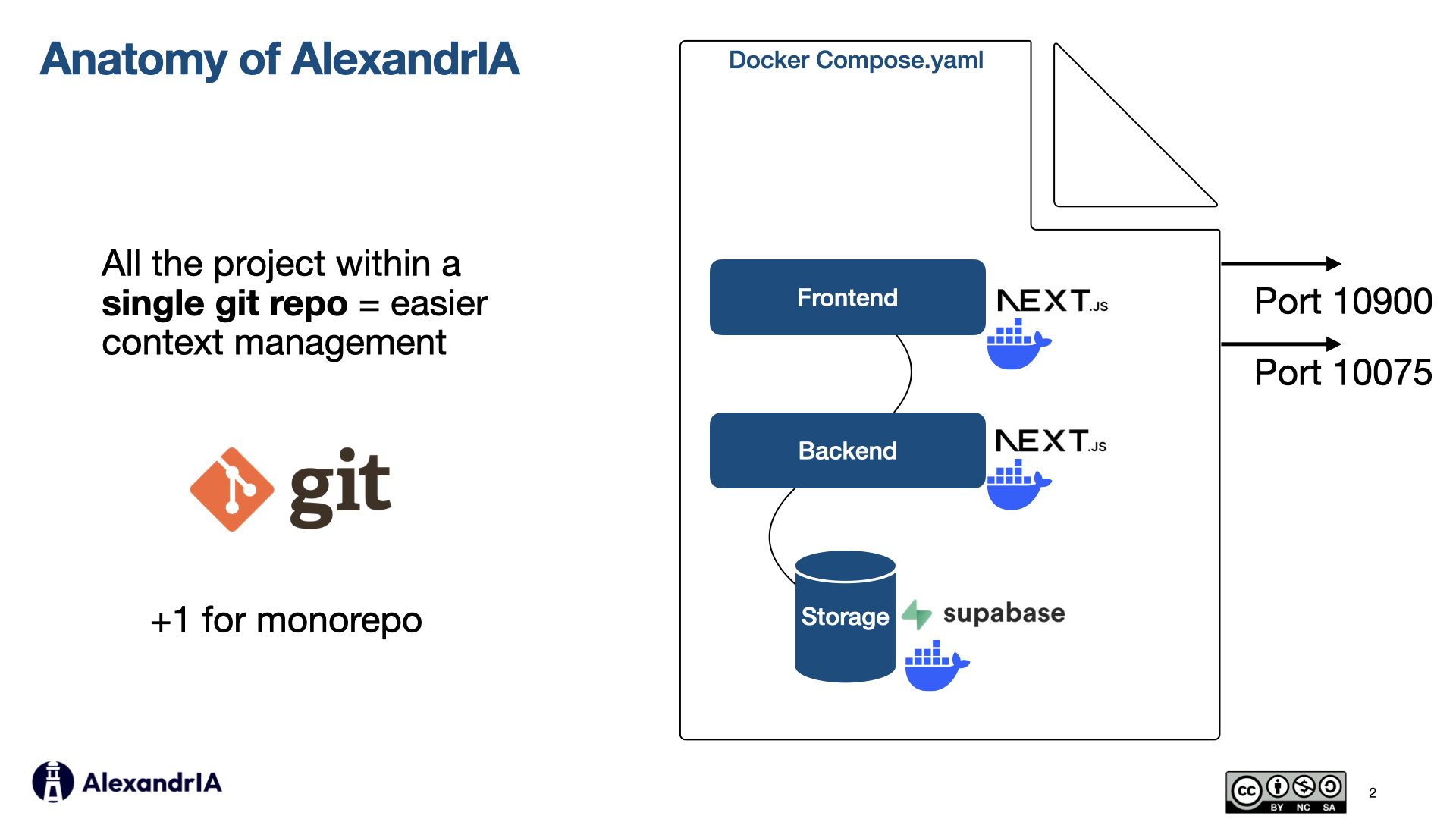
1. Structure your project for context
Monorepo over polyrepo - Keeping the entire project (frontend, backend, storage) within
a single git repo makes for more localized context, both for you and the model. No git submodules, no
complex dependency chains. One docker-compose.yaml to start and stop everything.
2. Save your cognitive bandwidth
Embrace your model's strong defaults - When Claude Code picks a tool, it shapes what gets built. Save your cognitive resource for your unique value prop rather than fighting the default stack. Focus your attention on architecture and product decisions, not boilerplate choices.
3. Design your feedback loops
Make feedback local and fast - Git pre-commit checks, linters (biome, typescript check,
knip for dead code), tests with explicit error messages, healthchecks on Docker containers,
API /health endpoints, and CI pipelines. All feedback loops runnable in one
command: make test. The faster your agent can detect issues, the less context it wastes on
dead ends.
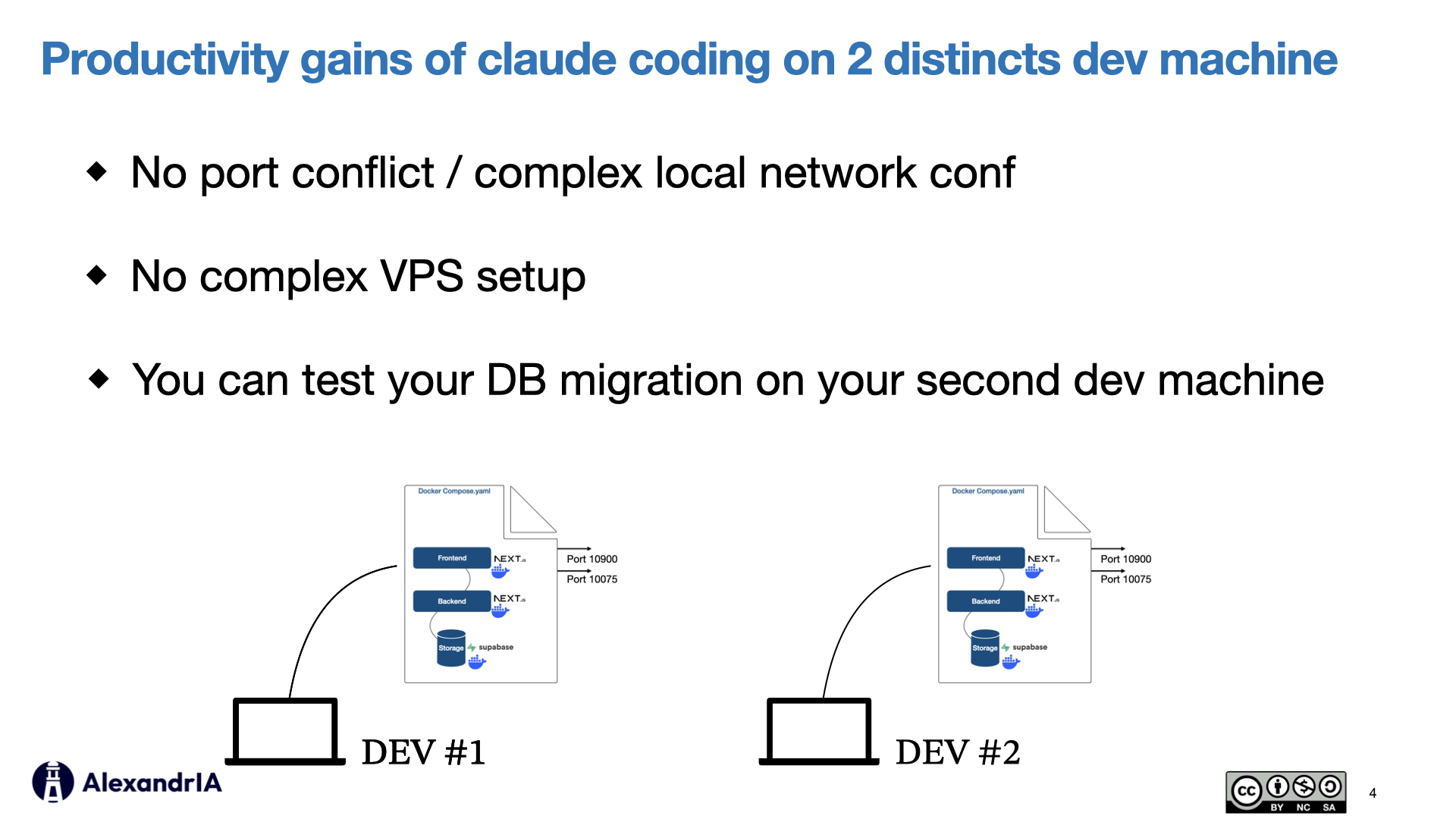
Bonus: Multi-machine setup
Use two dev machines for parallel work - Port conflicts, network configuration, and VPS complexity vanish when you run parallel Claude Code sessions on separate physical machines. You can even test your DB migrations on the second machine before merging.