Taxonomy of leading Generative AI architectures

Since November 2022 and the arrival of ChatGPT, content creation with artificial intelligence models has been booming[1]. The speed at which papers are being published in computer science and machine learning on Arxiv makes it unfeasible for researchers to read every contribution. This necessitates to quickly identify adaptations of existing models from groundbreaking contributions that will alter the field for years to come, such as "Attention is All You Need".
Most published architectures belong to a handful of families with interesting properties. We can identify four leading families of algorithms:
- VAE - Variational Auto Encoder
- GDM - Generative Diffusion Model
- GAN - Generative Adversarial Networks
- Transformers - Close to VAE, but with an attention mechanism
By examining the distinctions between these architectures, we can gain a deeper understanding of which model is best suited for our use case and the level of "creativity" it will demonstrate during inference.
Variational Autoencoders (VAE)
Variational Autoencoders combine ideas from autoencoders and probabilistic modeling. Like traditional autoencoders, VAEs are composed of two networks back-to-back. The latent space can be seen as a compressed representation of the concepts "learned" by the encoder network, usually in a much smaller dimension than the input space (e.g., millions of pixels of an image).
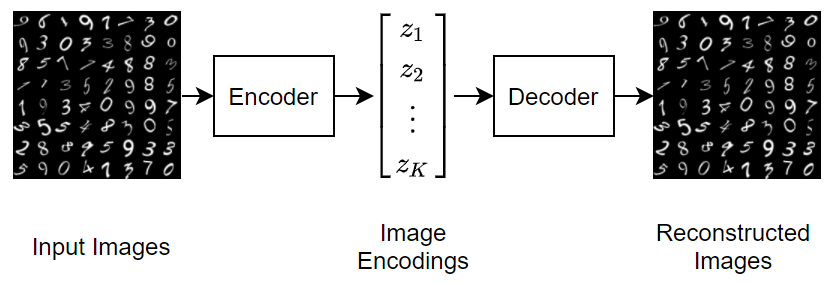
The key innovation of VAEs is that instead of encoding inputs to single points in latent space, they encode inputs to probability distributions over latent variables. The decoder randomly samples from this distribution when generating its output, allowing for the generation of new data with novelty from the training data. The degree of "creativity" of the model depends on the latent space and its ability to represent semantically linked concepts close to each other and unrelated concepts far apart.
For further reading, check out this great article by PhD Matthew N. Bernstein.
Generative Diffusion Models (GDM)
Generative diffusion models are inspired by thermodynamics and the physical process of diffusion, where a concentrated substance gradually spreads out and becomes more uniform over time. You can think of thermal conduction as a comparison, where heat energy diffuses from a region of higher temperature to a region of lower temperature within a material, driven by kinetic energy transfer between molecules until thermal equilibrium is reached.

In generative diffusion models, data is progressively diffused by adding noise, and then a reverse process is applied to denoise and reconstruct the original data, akin to reversing the diffusion of heat to restore the initial temperature distribution. Key papers in this field include "Denoising Diffusion Probabilistic Models", (2020) by UC Berkeley researchers, which significantly improved upon the initial 2015 paper "Deep Unsupervised Learning using Nonequilibrium Thermodynamics".
Lilian Weng proposes two great posts on diffusion models: What are Diffusion Models? and Diffusion Models for Video Generation.
Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs) were introduced in 2014 by Ian Goodfellow and colleagues in their seminal paper "Generative Adversarial Networks". GANs take inspiration from game theory to train two neural networks that compete against each other in a minimax game. The key intuition behind GANs is to frame the generative model as an adversarial game between two players:
- Generator: Creates fake data to fool the discriminator.
- Discriminator: Tries to distinguish between real and fake data.
As training progresses, the generator gets better at creating realistic fake data, while the discriminator improves at detecting fakes. This adversarial process pushes both networks to improve until the generated data is indistinguishable from real data. The connection to game theory comes from framing this as a two-player minimax game, where the discriminator tries to maximize its ability to detect fakes, while the generator tries to minimize the discriminator's success. At equilibrium, the generator produces data indistinguishable from real data.
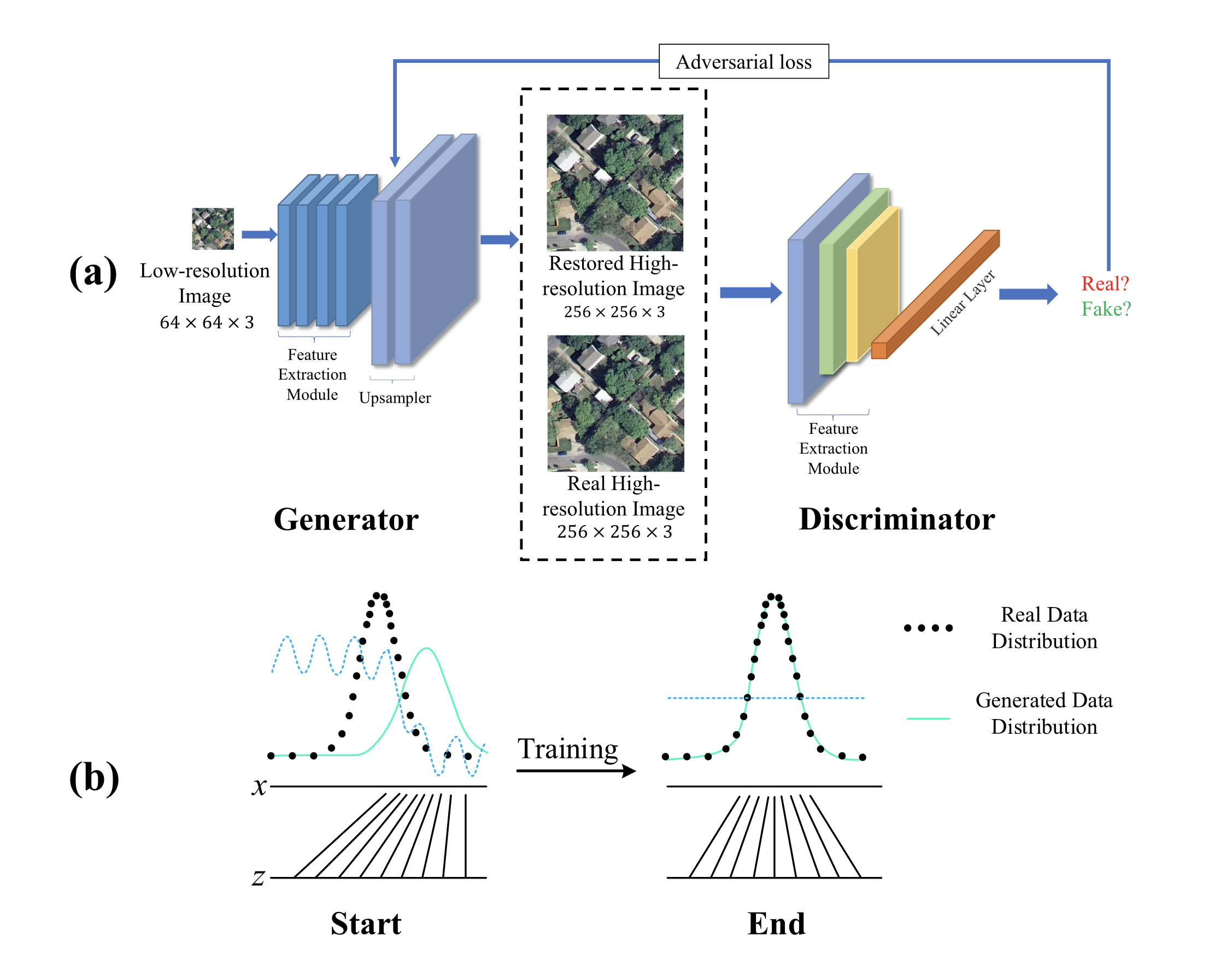
GANs also relate to reinforcement learning (RL) in that the generator can be viewed as an agent trying to maximize its reward (fooling the discriminator). Some GAN variants, like SeqGAN, explicitly use RL techniques to train the generator.
Transformers
Transformers were introduced in 2017 by Vaswani et al. in their influential paper "Attention Is All You Need". The key innovation of Transformers is the use of self-attention mechanisms to process sequential data, allowing the model to dynamically focus on relevant parts of the input when producing each element of the output. They are not so different from VAEs, as transformers also have an encoder and a decoder, with the main difference being the attention mechanism.
The intuition behind Transformers and their attention mechanism can be understood through these key points:
- Self-Attention: Allows the model to weigh the importance of different parts of the input data dynamically.
- Parallel Processing: Enables efficient handling of long-range dependencies in sequential data.
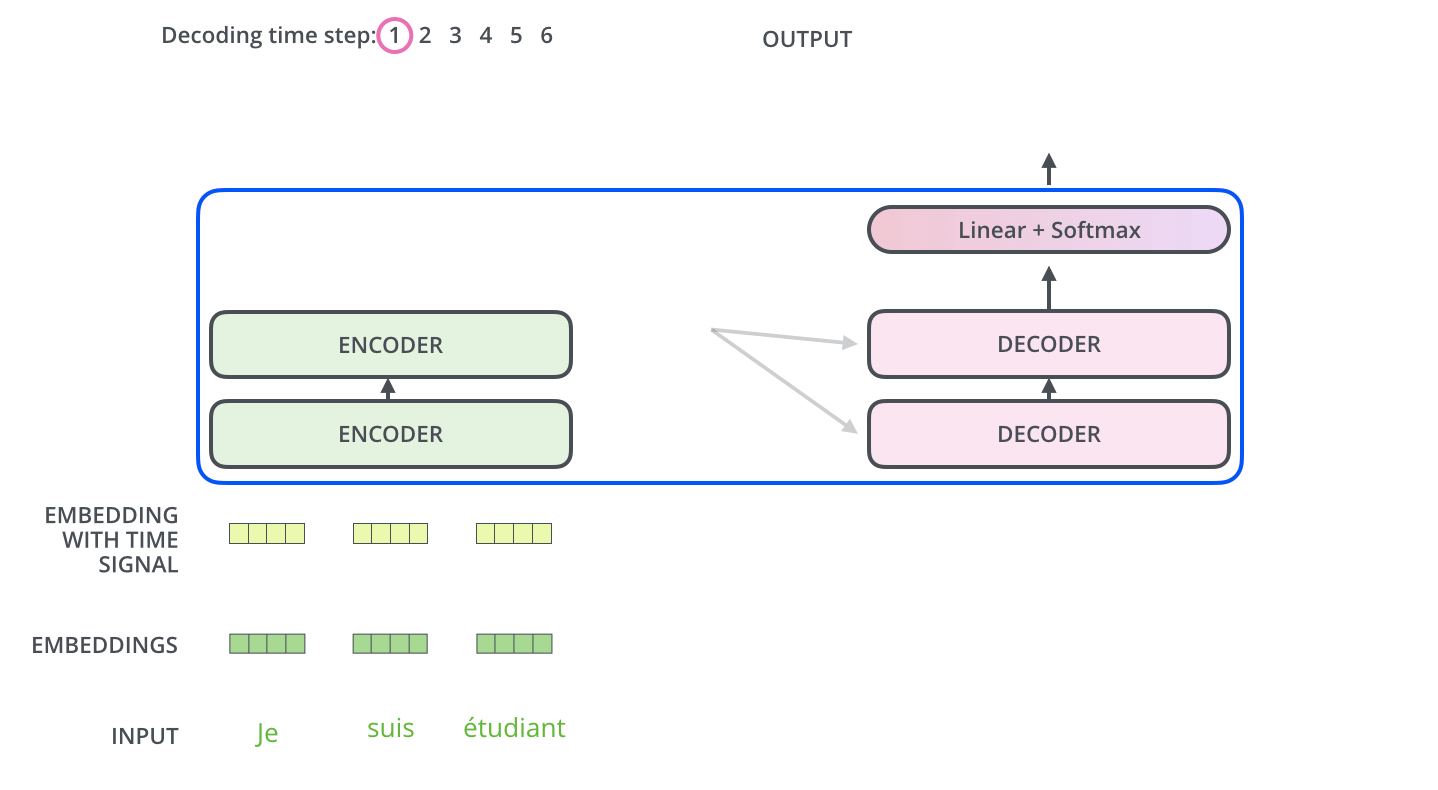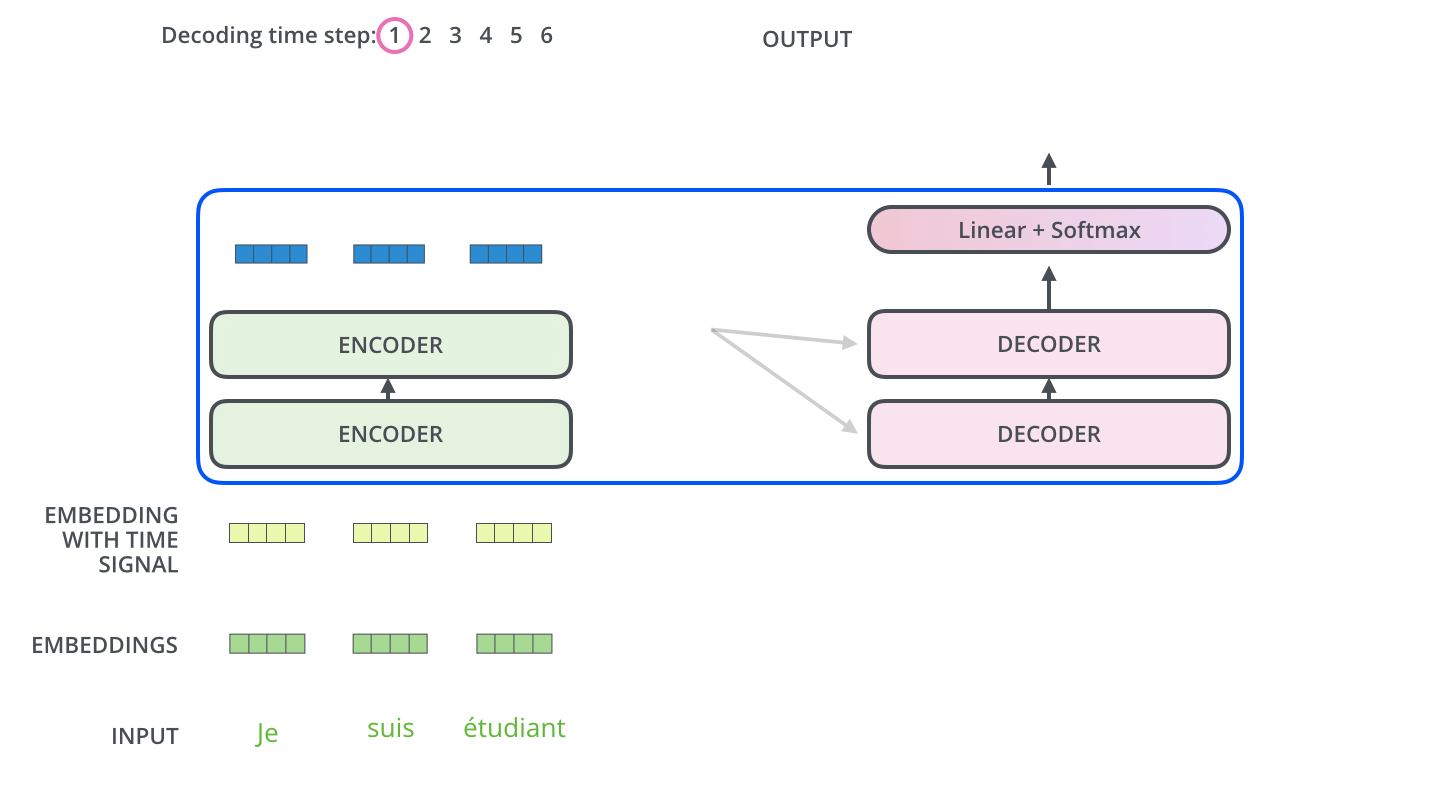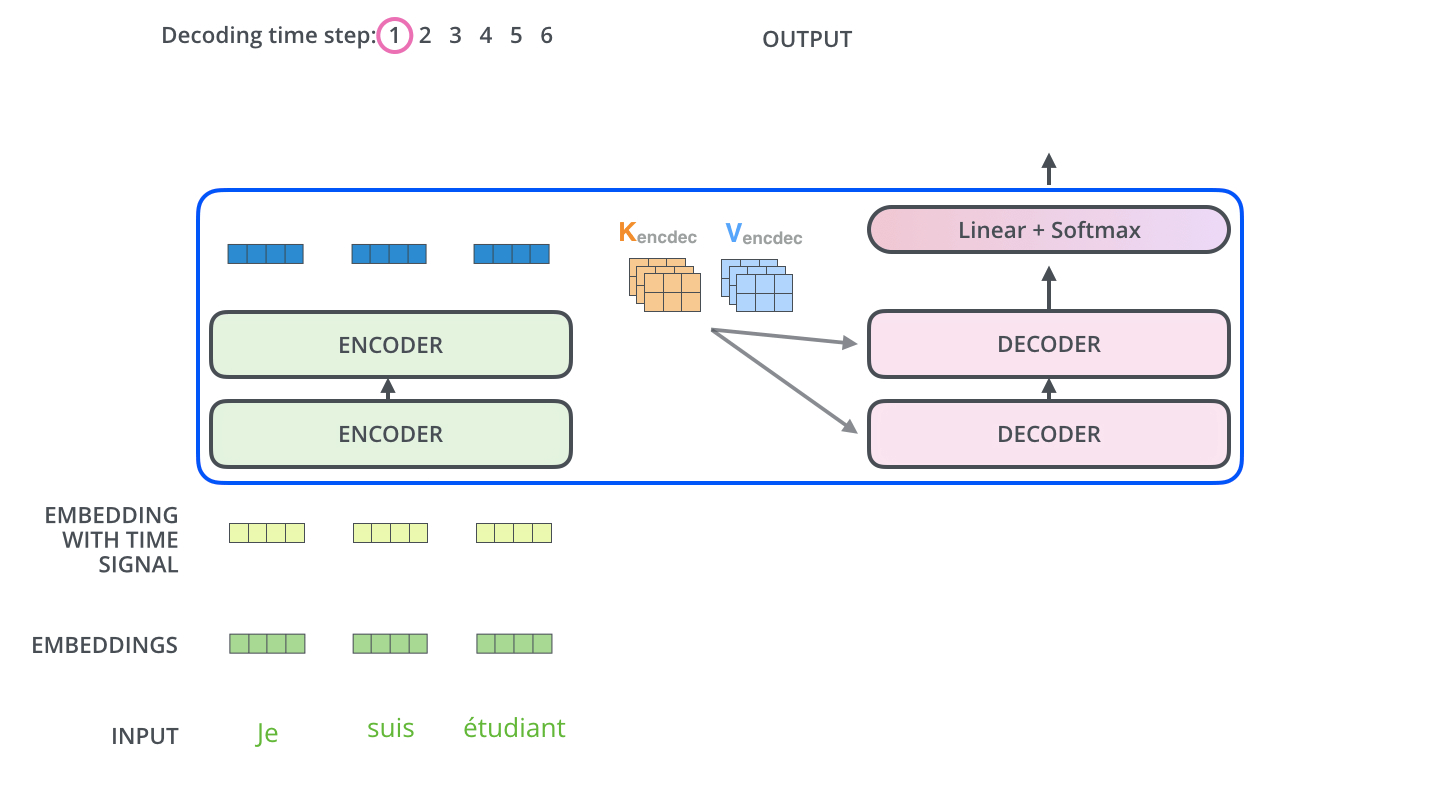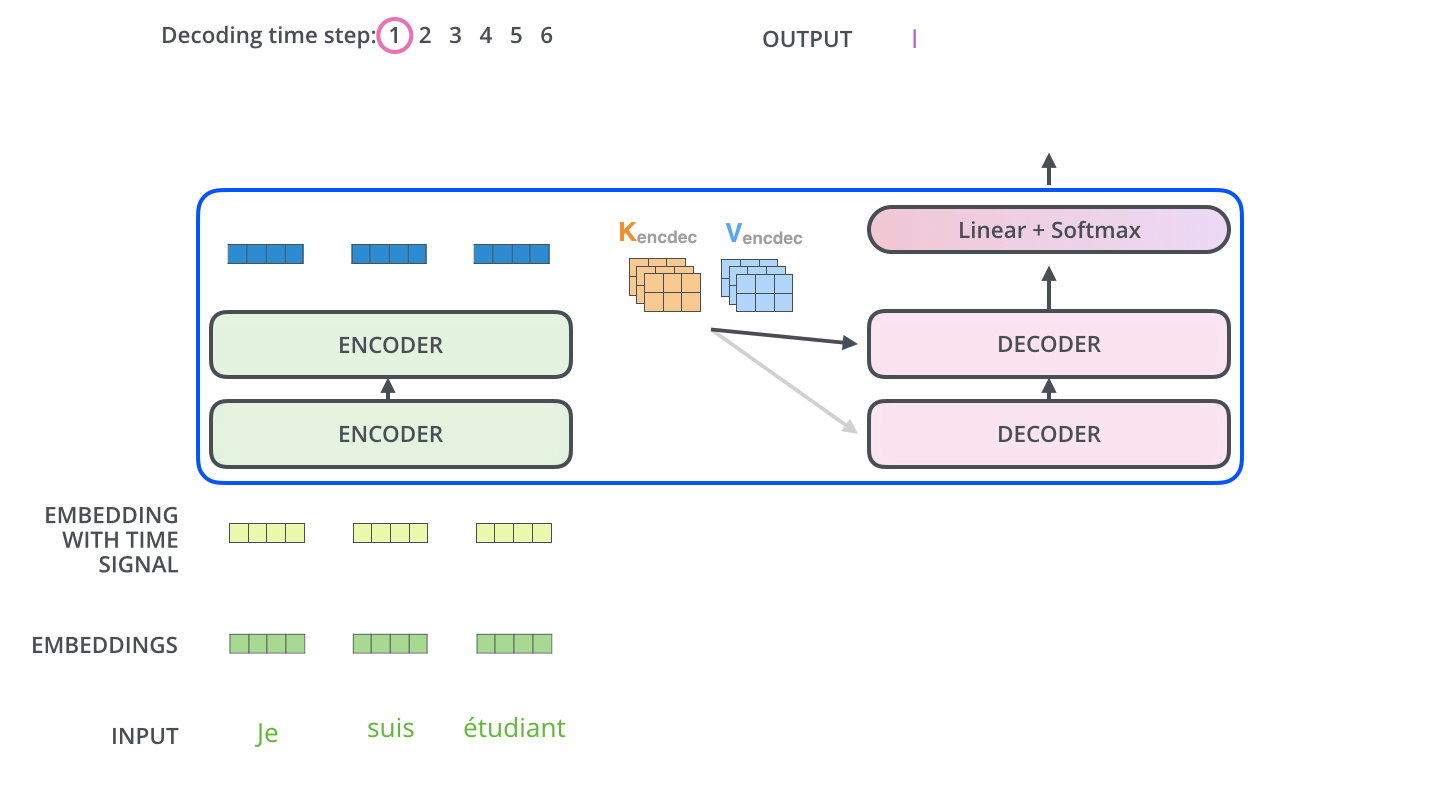
Transformers have become the foundation for many state-of-the-art models in natural language processing, including BERT, GPT, and T5. Their ability to handle long-range dependencies and parallel processing has made them particularly effective for tasks involving language understanding and generation.
Transformers and attention mechanisms got a lot of coverage, below are some great resources:
- The Illustrated Transformer by Jay Alammar - An excellent visual guide to understanding Transformers
- The Annotated Transformer - A line-by-line implementation of the Transformer model
- Attention? Attention! by Lilian Weng - A comprehensive overview of attention mechanisms
Several large language models (LLMs) published since 2020 are based on the transformers architecture (many are decoders only) using the attention mechanism we discussed. Among the four model families discussed, it's interesting to see the intuition researchers took from other domains such as thermodynamics (for diffusion models) or game theory (for GANs).
Applying this expert knowledge of existing scientific discoveries in the model creation process has enabled researchers to leapfrog performance on several tasks, let's see what next approach brings an order of magnitude improvement to the existing literature.