Unleash Multiprocessing with Python and gRPC
Introduction
If you’re reading this, it’s likely you’re in the optimization phase of your project and want to reduce your application’s runtime. In this article, I aim to answer the following question:
How to address an embarrassingly parallel workload in Python using gRPC servers?
I’m a freelance machine learning engineer, and I got called for such a project: to reduce the runtime of a computer vision workload. I’ve taken the gist out of this experience and here’s what I learned.
I split this article into two parts: first a light theoretical refresher, then a practical tutorial:
- We’ll briefly highlight the differences between multi-threading and multiprocessing, pinpointing which use cases are better addressed by one or the other.
- Then we’ll get our hands dirty and walk through a use case of optimizing a computer vision app.
We’ll work on a simple optical character recognition (OCR) use case but feel free to adapt it to your workflow! Bonus: Expect war stories and gRPC tips & tricks along the way!
ℹ️ The code and docker images for this boilerplate are freely available on my eponymous GitHub repo fpaupier/grpc-multiprocessing
If there are no strong prerequisites for this article, understanding the core concepts of gRPC will help.
Multiprocessing, multi-threading, what’s the difference?
TL;DR:
- Use multi-threading for I/O bounded tasks.
- Use multiprocessing for compute-heavy (CPU/GPU bounded) tasks.
Now, “Why?” you ask me:
- multi-threading can speed up your program execution when the bottleneck lies in a network or an I/O operation.
- Multi-threading happens within a single processor, and a processor executes a single instruction at a time.
Wait, so there’s no speedup on my compute-heavy task when doing multi-threading?
— Correct.
All multi-threading can do is hiding the latency of I/O and networks operations. And that’s already a lot!
Let’s say your python code makes a gRPC call that’s taking some time to return; with multi-threading, the processor will switch to the next available thread where an instruction is ready to be executed instead of blocking until the gRPC server returns the response.
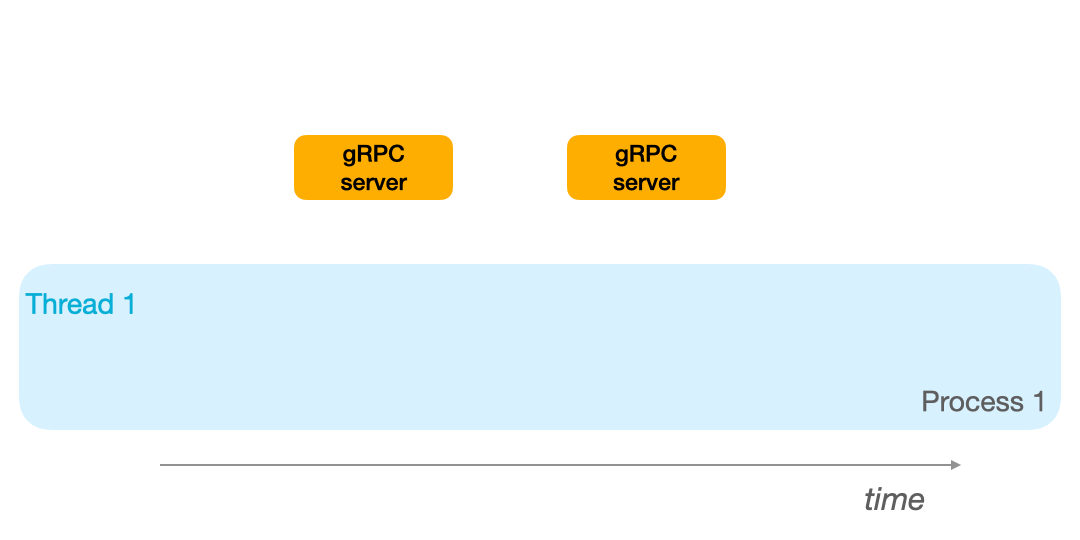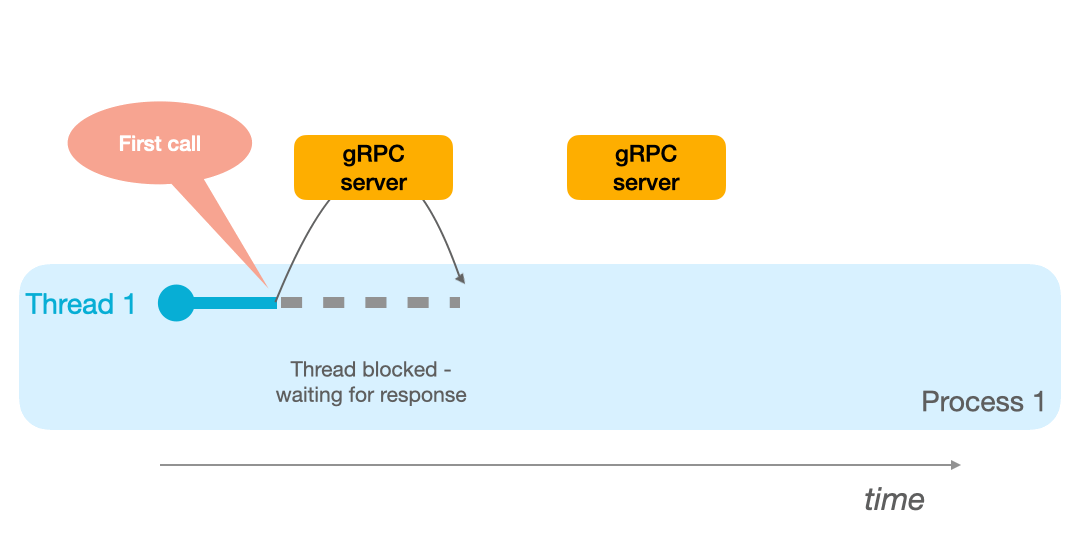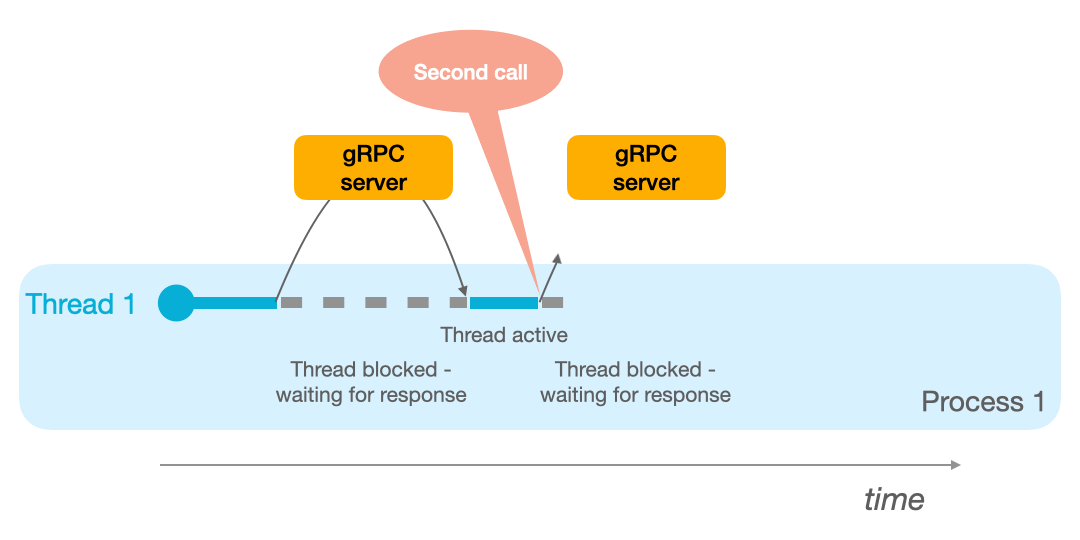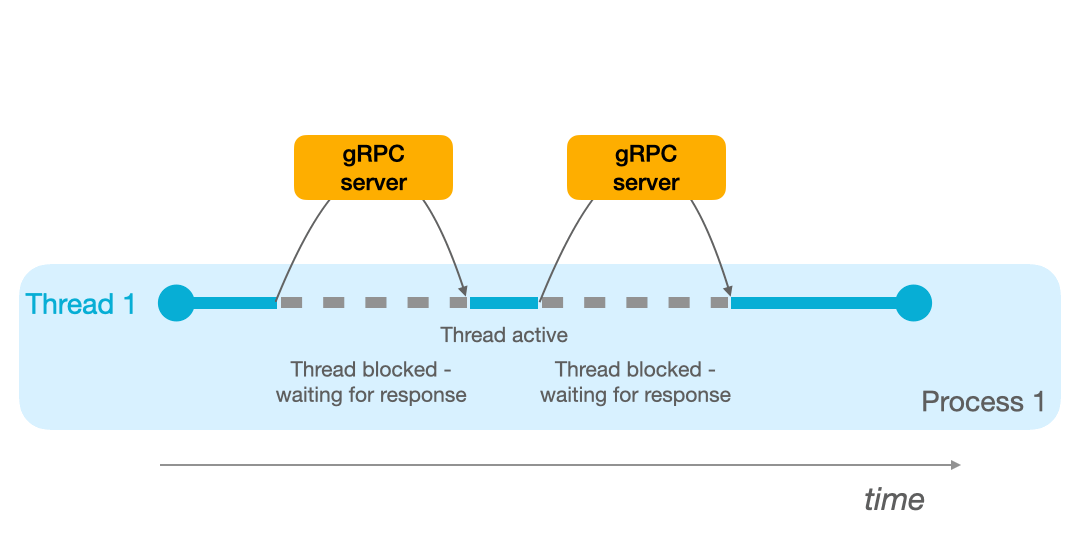
If you have a single thread available, as in the animation below, the thread blocks until he receives the RPC response.

This means that if you have 2 remote procedure calls to make, in the mono process/mono thread model, you will have to wait until the first response is received before sending the second request. As seen in the GIF below:
On the other hand, if your process has 2 threads available, it can switch to thread 2 when the first procedure call is underway:
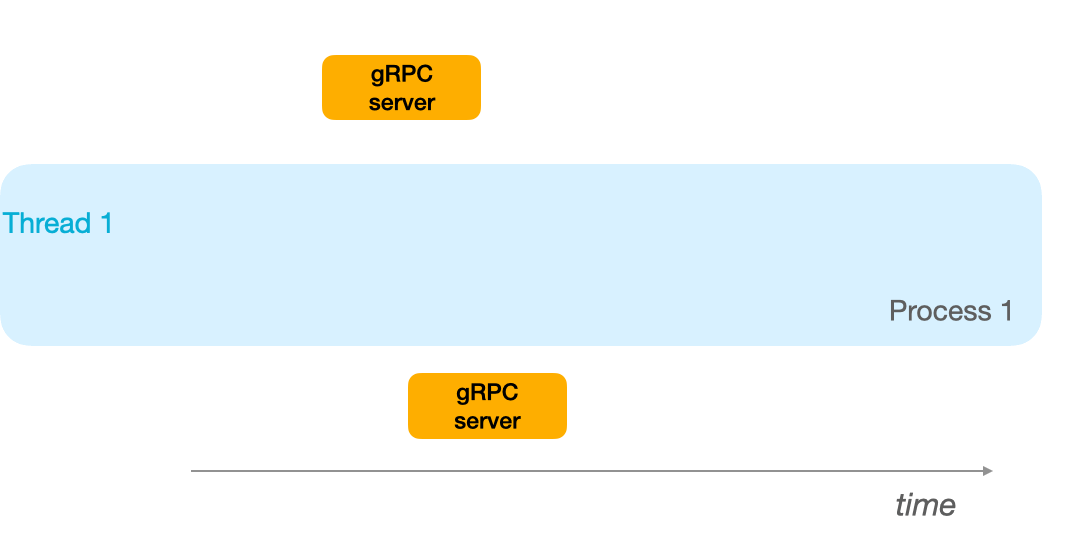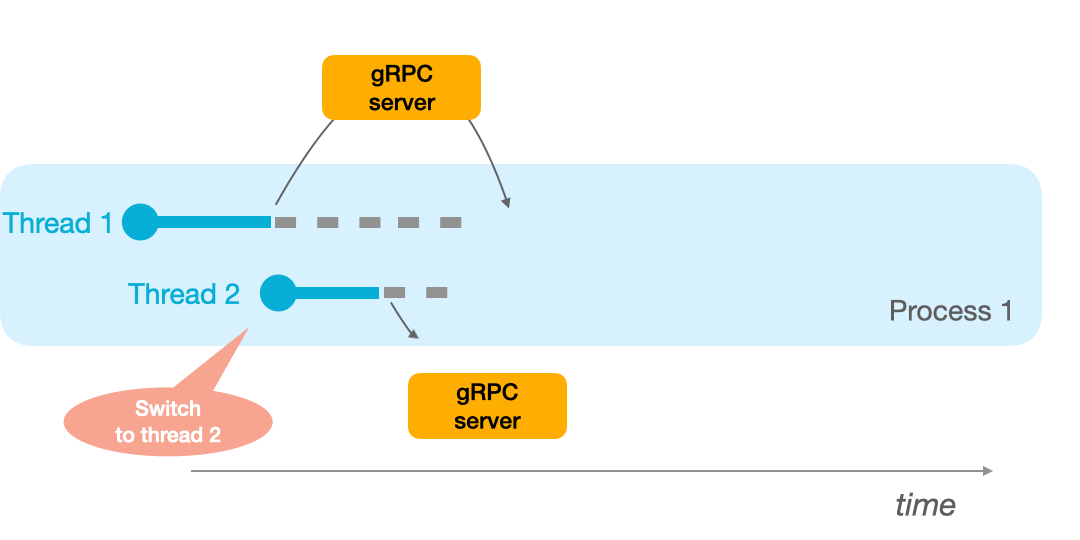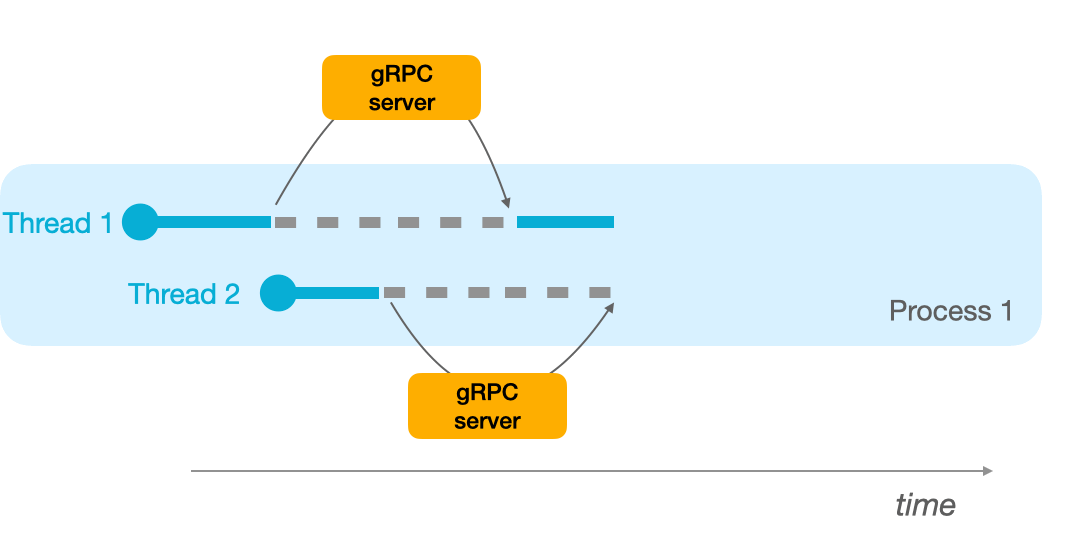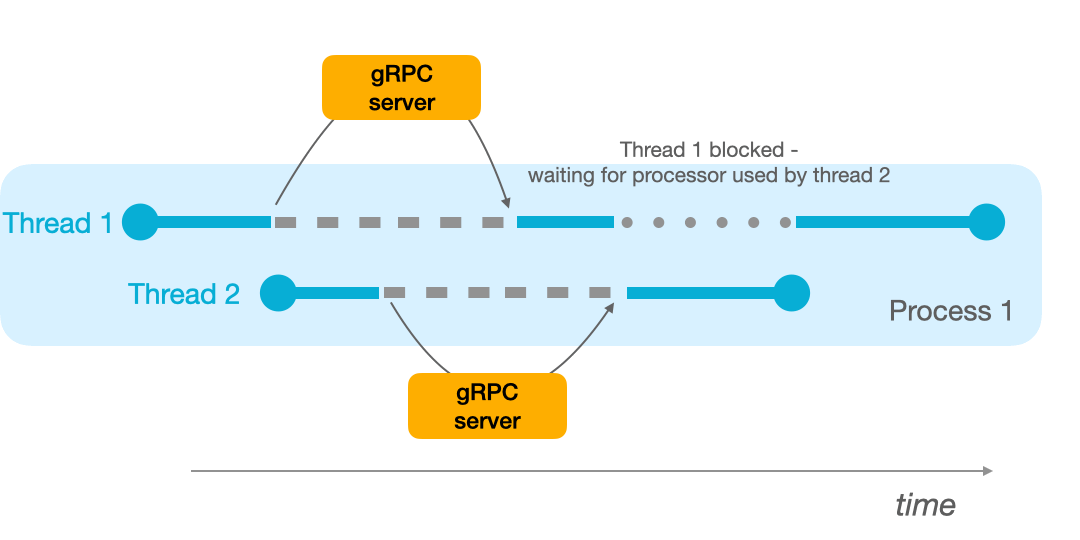
That’s already a big improvement over mono-threading! An alternative is to use multiprocessing so that both calls are emitted simultaneously, that’s what happens with multiprocessing.
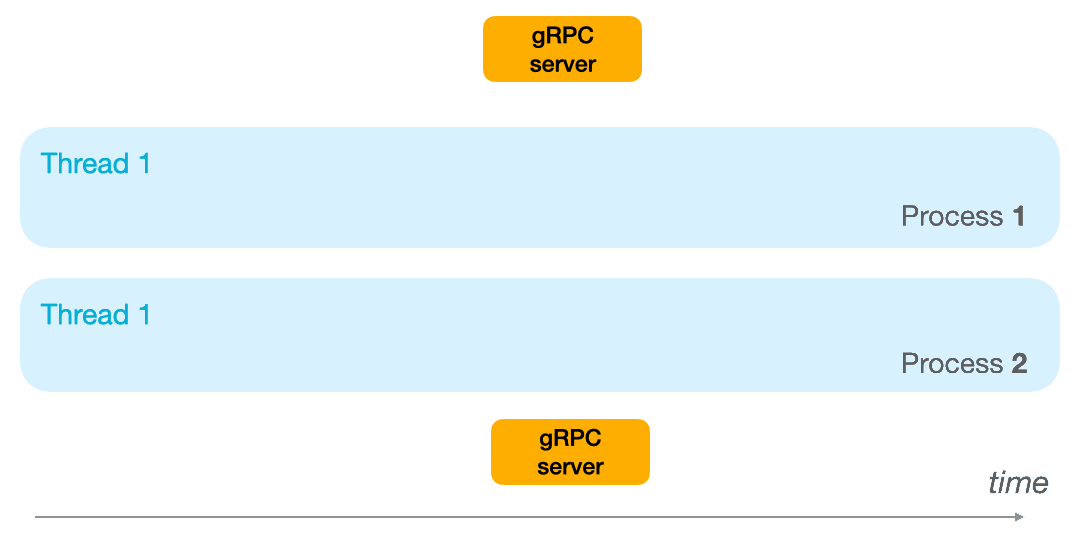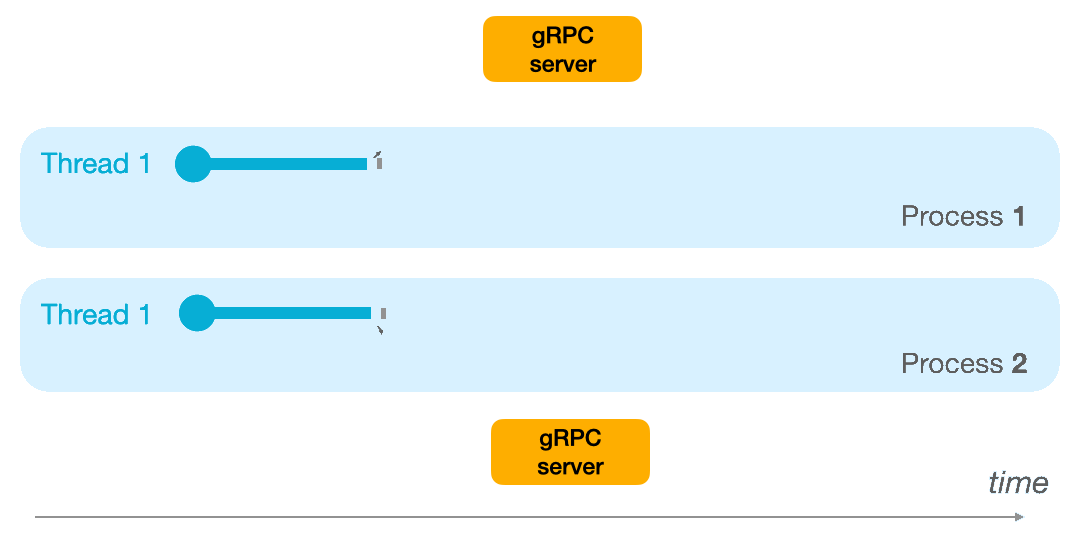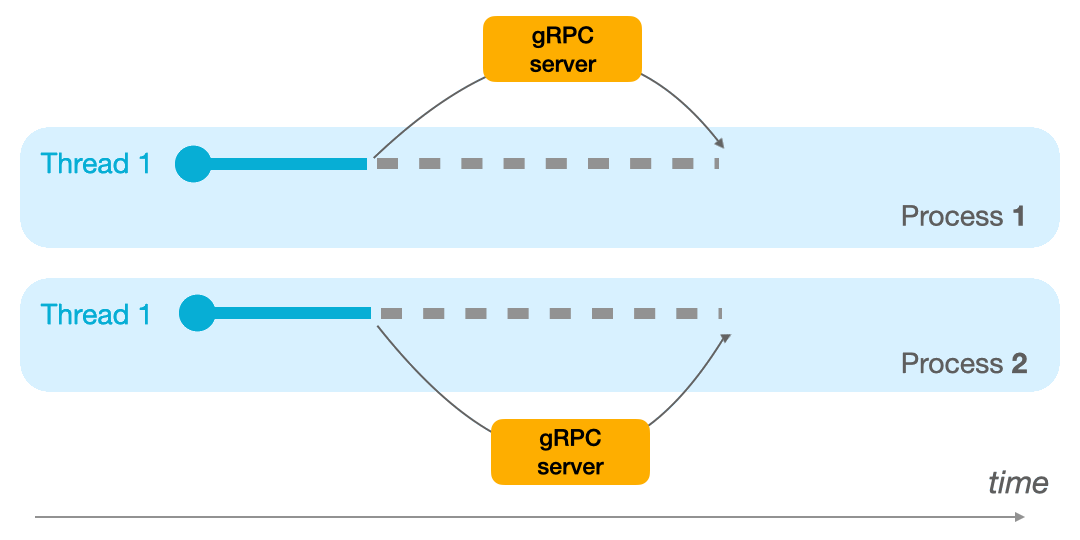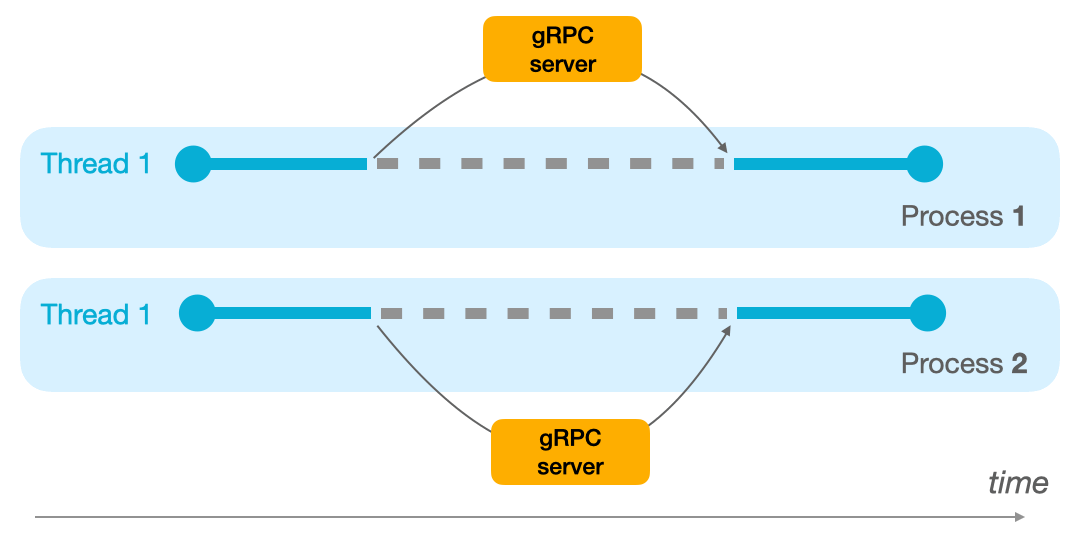
- With multiprocessing, you allocate several processors to execute the task at hand. Since each processor can execute a single instruction at time t, with several processors you can execute several tasks at time t. Thus, you can achieve parallelism and execute several instructions simultaneously, one on each processor.
Multiprocessing is your best friend when you have CPU/GPU hungry operations to run en batch with no synchronization to perform between the tasks or their results.
Below, an example with two mono-thread processes.
To wrap up this theoretical intro, the Python concurrent.futures module brilliantly illustrates this difference of uses cases:
- They illustrate their multi-threading component, the ThreadPoolExecutor, with a code snippet calling several websites asynchronously.
- The ProcessPoolExecutor, on the other hand, is used for a compute-heavy task — checking whether a number is prime. Here, all processes will work simultaneously, each on a different number, to find if it’s a prime.
I won't go in-depth on the differences between multiprocessing and multi-threading. For more context on this vast topic, I recommend this excellent article from the Content Square engineering team.
Now that we’re good on the theory, let’s get our hands dirty on a real-life example!
Practical Example: Reducing your pipeline processing time with multiprocessing
A minimal reproducible example with a Computer Vision pipeline.We're building an OCR pipeline, and we want to detect text from photos to ease their indexing and information retrieval. Here are some sound assumptions we can make:
- Each photo is independent of others. Therese is zero synchronization required between the processing of two different pictures.
- Image processing is a CPU/GPU-bounded task, making it an ideal candidate for multiprocessing.
To replicate this example, clone the gRPC-multiprocessing repository and run the Dockerized app:
This use case checks all the boxes of a good multiprocessing candidate!
The core business logic of this project lies in the server.py and its get_text_from_image
function
def get_text_from_image(img: bytes) -> str:
"""
Perform OCR over an image.
Args:
img (bytes) : a pickled image - encoded with openCV.
Returns:
The text found in the image by the OCR module.
"""
# By default OpenCV stores images in BGR format and since pytesseract assumes RGB format,
# we need to convert from BGR to RGB format/mode:
img_rgb = cv2.cvtColor(pickle.loads(img), cv2.COLOR_BGR2RGB)
return pytesseract.image_to_string(img_rgb)
️Note: To run the OCR experiment and reproduce the results, you can run the dockerized app provided in the repo:
#!/bin/bash
git clone git@github.com:fpaupier/gRPC-multiprocessing.git
cd gRPC-multiprocessing
cp .env.example .env # adjust the nº of workers as you wish
docker-compose up
# INFO [/usr/app/client.py:126]: OCR Test client started.
# INFO [/usr/app/client.py:115]: Reading src image...
# ...
This project is a minimum reproducible example of clients sending batches of images to gRPC
servers.
At this point, feel free to docker-compose up the project and compare run times for different
configuration values, namely NUM_WORKERS and NUM_CLIENTS
Measurements
Experiments were run on a 2017 MacBook Pro with a 2.3 GHz Dual-Core Intel Core i5 processor and 16 GB memory. As expected, the runtime was halved when increasing from one to two processors.
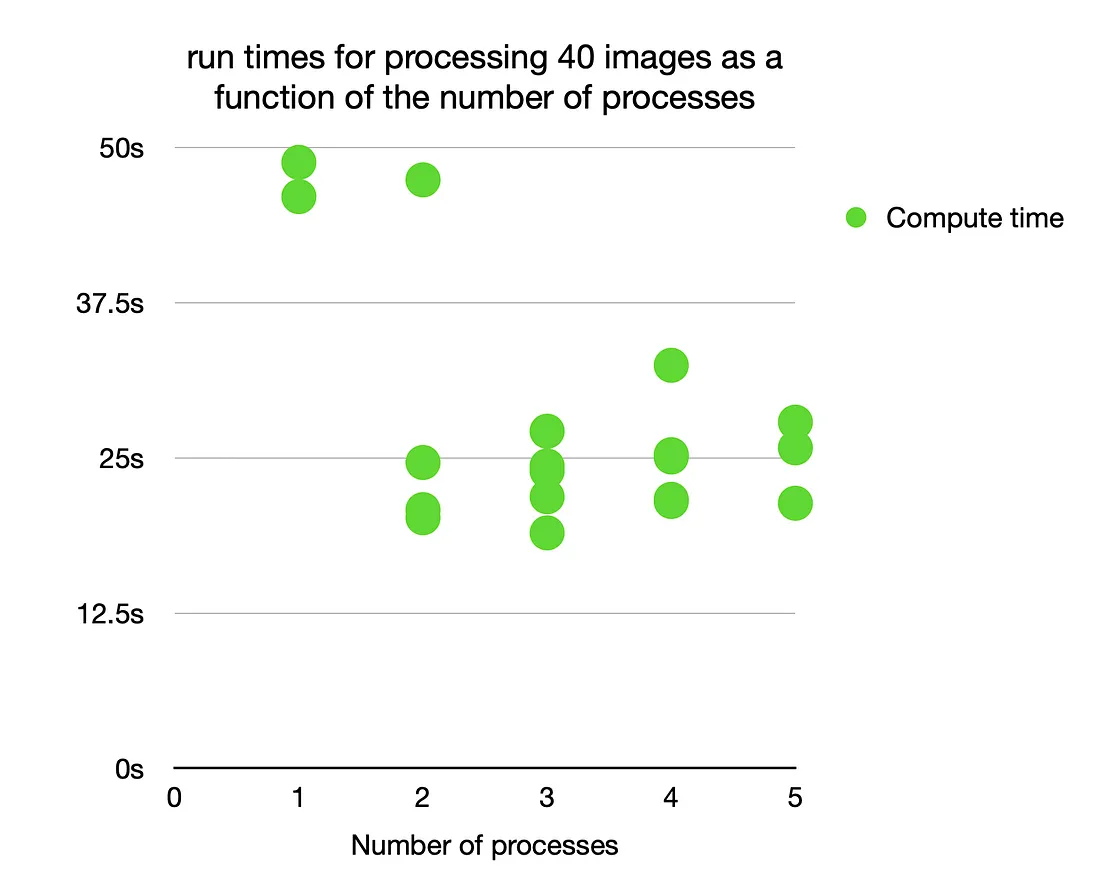
Since I only have 2 physical CPUs on my machine, increasing the number of processes does not translate in more speedups.
The devil is in the details, let’s take a close look at the implementation techniques to keep in mind when building a gRPC multiprocessing pipeline.
Overview of the Pain Points We’ll Address
Server-Side Challenges
- Why the intuitive solution using
ProcessPoolExecutordoesn’t work. - Introducing the
multiprocessingmodule from Python’s standard library. - Setting up processes before starting the server.
- Enabling port reuse for workers.
Client-Side Challenges
- Breaking down workloads into independent tasks.
- Setting up as many clients as there are workers.
- Implementing proper joining logic for processing results.
From 1 to n — Multiprocessing with gRPC at the Server-Side
Source: https://github.com/fpaupier/gRPC-multiprocessing/blob/main/server.py
Observation: The simple solution does not work
Multiprocessing with gRPC is hard because the intuitive solution of passing a ProcessPoolExecutor
at the server initialization does not work.
import grpc
from concurrent import futures
server = grpc.server(
futures.ProcessPoolExecutor(max_workers=5), # ← HERE: Would be ideal but does not work.
options=[ # See https://github.com/grpc/grpc/issues/14436
("grpc.max_send_message_length", -1),
("grpc.max_receive_message_length", -1),
]
)
This code won’t produce the expected result. That’s pretty frustrating since it’s possible to handle multi-threading with gRPC, by using a concurrent.futures.ThreadPoolExecutor for the server initialization.
This gRPC incompatibility with ProcessPoolExecutor has been documented since, at
least,
Feb. 2018 with no change as of Aug. 2021 — see issue
#14436 on gRPC’s GitHub.
Here’s the trick, we’ll take the problem the other way around: instead of initializing a gRPC server and telling it to spawn several processes (which the gRPC lib does not currently support), we’ll spawn several processes and start a single gRPC server in each process.
You now have the secret sauce! Let’s go through the critical steps and caveats to avoid when making your single processor gRPC server evolve towards multiprocessing.
The multiprocessing module to the rescue
multiprocessing
is a module from Python standard library, it “allows the programmer to fully leverage
multiple
processors on a given machine”. That sounds like what we’re up to!
Here’s how
it’s implemented in the main() of server.py:
def main():
"""
Inspired from https://github.com/grpc/grpc/blob/master/examples/python/multiprocessing/server.py
"""
logger.info(f'Initializing server with {NUM_WORKERS} workers')
with _reserve_port() as port:
bind_address = f"[::]:{port}"
logger.info(f"Binding to {bind_address}")
sys.stdout.flush()
workers = []
for _ in range(NUM_WORKERS):
worker = multiprocessing.Process(target=_run_server,
args=(bind_address,))
worker.start()
workers.append(worker)
for worker in workers:
worker.join()
The rest of the file is also important, but it’s more plumbing. In a nutshell:
- Reserve a port (here 13000 with the
_reserve_portcontext manager). - Start
NUM_WORKERSusingmultiprocessing.Process, each running the_run_serverfunction. - Each
_run_serverinstance creates a gRPC server, adds the OCR service, and starts it.
Et voilà! Now for the protips:
- Make sure to enable port re-use for your workers. It’s a two steps process.
-
Enable the option at your gRPC server initialization
("grpc.so_reuseport", 1) -
In the
_reserve_portcontext, ensure the socket port is re-usablesock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEPORT, 1)
-
Enable the option at your gRPC server initialization
- Be careful of data race (i.e., if two processes need to access a shared resource, like a file, a network connection, those are hard to reproduce/debug behaviors)
Client-Side — Leveraging a pool of gRPC servers
Source: https://github.com/fpaupier/gRPC-multiprocessing/blob/main/client.pyIn the part above, we saw how to start a pool of gRPC servers. To make the most out of this pool of resources, you need to make some adjustments to your client code. If you open a single gRPC channel and start querying it from a single Stub, you’re going to hit a single gRPC server and won’t see any improvement.
Instead, you need to open one channel for each server you want to leverage. If there are 3 gRPC servers, you’ll need to have at least 3 gRPC clients opened to distribute your load. I say at least since you can experience speed up by conserving the same number of servers but increasing the number of clients.
Protip: In the server code, print the server process ID to see which server receives your request
and
ensure you distribute your load as expected. import os; os.getpid()
In the client code, similar to what we do in the server.py, we start a pool of
processes
using a
multiprocessing.Pool
Each process will instantiate a gRPC channel. Make sure to enable the option to re-use port in
the
channel initialization ("grpc.so_reuseport", 1)
We can now distribute the batch of image processing over the pool using the
worker_pool.map()
function that will distribute the load to each of the gRPC channels.
For the code subtleties, pay attention to the:
_initialize_workerand the use of theatexitto close channel connection.- The use of global variable for
channelandstubinitialization.
Closing Thoughts
Multiprocessing is a trial and error process. Each use case will require a fine-tuning of the appropriate number of workers to process your workload. Profile resources consumption for different n° workers / client for your machine and decide accordingly..
For instance, I observed a 2x speedup going from a single processor to two processors on an image processing workload, but when going from 2 to 4 workers, I didn’t get another 2x speed up factor overall. The bottleneck was no longer the batch processing but when persisting the results into the database, but that’s another story.
Also note that debugging in a multiprocessing context is notoriously hard. Exception at the server level and the client-server communication level might not be explicitly raised, leaving you with cryptic error messages.
References
- This article strongly builds on top of Google example on how to use gRPC for multiprocessing. https://github.com/grpc/grpc/tree/master/examples/python/multiprocessing.
- This article from the folks at ContentSquare Engineering https://engineering.contentsquare.com/2018/multithreading-vs-multiprocessing-in-python/.
- I also took inspiration from those slides for my GIFS showing the interest of multi-threading in remote procedure call context.https://slideplayer.com/slide/244540/%20f.
- Cover image by Isaac Quesada from Pexels