Introducing a tensorflow server sidecar

Introduction
Tensorflow serving offers a convenient solution to deploy models in production. To deploy a new
version of a predictive model for inference, you can build a custom
tensorflow/serving
image
containing the new version of your model, push it on a container registry and deploy the
image.
This approach has some drawbacks:
- It requires you to build and push a custom
tensorflow/serving imagefor every new version of your model - It mixes ops concerns with data scientists concerns - It is not clear whose responsibility it is to build and push the new image
The Pattern
In this article, I introduce a pattern to continuously deploy new versions of an ML model on an inference server. The code illustrating this pattern is freely available on my GitHub repository sidecar-pattern_tf-serving, a docker image is also available to experiment the pattern.
The two containers at play are:
- A vanilla
tensorflow/serving - A
model_poller
This pattern emulates the online-prediction feature of Google Cloud ML. Note: This is not about serving multiple models but rather, serving the latest available version of one model.
Visual Description
In this pattern, Data Scientists push a compressed saved_model (the artefact
resulting
from the training) on a storage bucket. And
that's it. It
is automatically downloaded on the server and tensorflow/serving start to serve it. My drawing
below
sums it up.
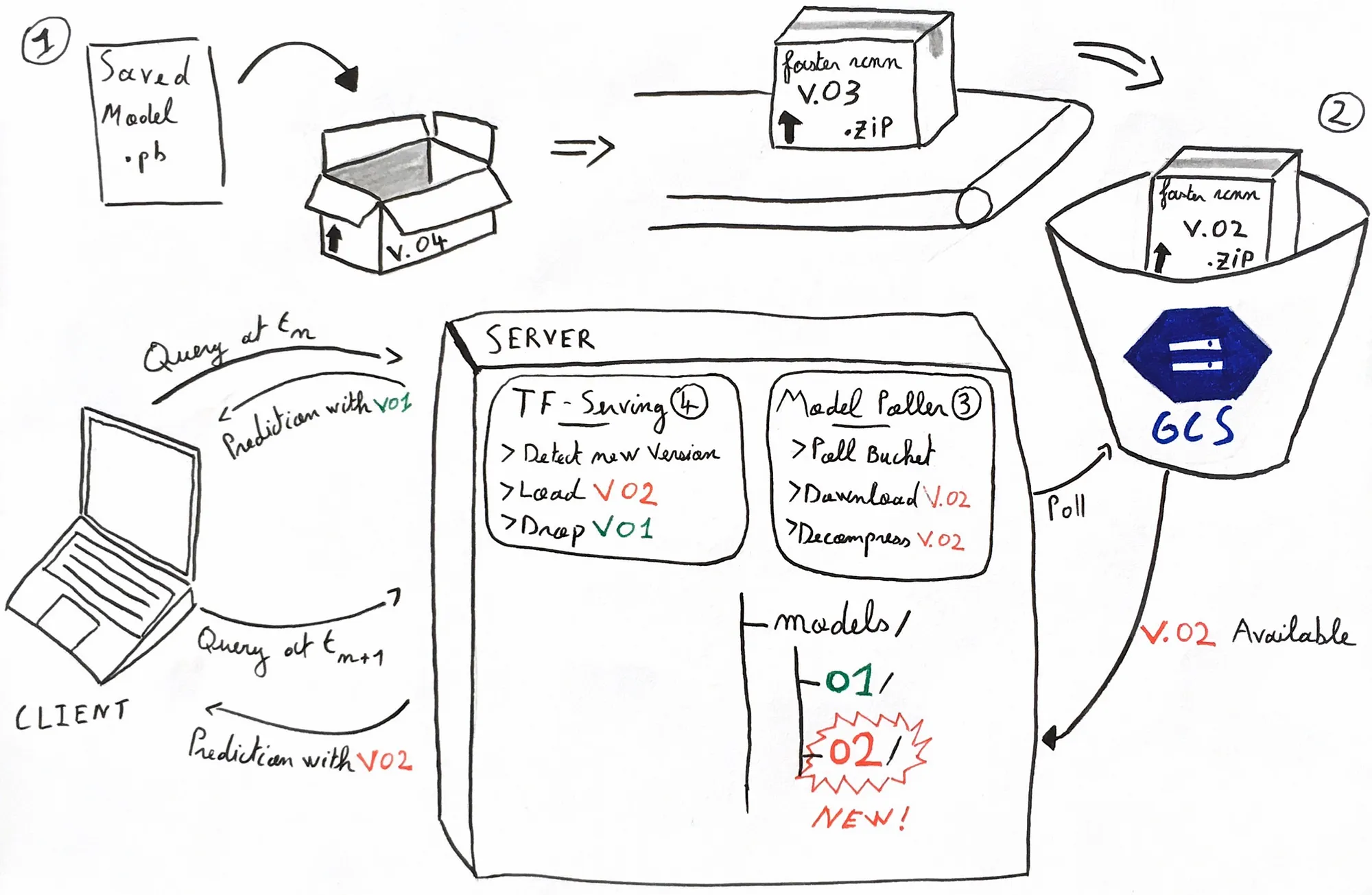
Let’s go through it, one step at a time
In the initial situation, we have one model being served in its first version 01.
When
clients query
the tensorflow/serving REST API, they get predictions performed by the v. 01 of the
model. The
server runs two containerized application, tensorflow/serving and
model_poller.
→ We tweaked the models’ hyper parameters, retrained it, and it outperforms v. 01.
Great! We now want to deploy v. 02 of our awesome model.
-
Data Scientists export
the model as a
saved_model. The folder looks like this :It is important to name the folderbash# Structure of the versioned model folder tree . -L 3 0002/ | |--saved_model.pb | |--variables/ | | | ...000xwherexis your model version number. Tensorflow/serving will load any new version it finds. - Now zip it and ship the model on a storage bucket. Having one bucket per model is a best practice.
-
On the server, your
model_pollerapp continuously polls the model bucket for a new version of the model. Ah! It just detected thatv. 02is available. It downloads the latest version of the model and unzips it in the folder used bytensorflow/servingto source the models to serve. -
tensorflow/servingcontinuouslylsits model source to see if any new model is available. Oh! It detects that a new versionv. 02of the model is available. The version manager loads the new version and unloads the old one from memory.
02 of the model.
Summary
The client experiences no service downtime and this pattern clearly delimits the scope of data
scientists: pushing a new zip model in a storage bucket. The model is no longer
coupled
to the
serving application. The Data Engineer can focus on fine-tuning the pipeline (tensorflow/serving
settings, a new implementation of the model_poller, etc.) without disrupting its
data
scientists
colleagues work.
References
- Design patterns for container-based distributed systems, Brendan Burns, David Oppenheimer, https://static.googleusercontent.com/media/research.google.com/fr//pubs/archive/45406.pdf
- The official tensorflow/serving documentation can be helpful, especially the part about loading a new version of a model https://www.tensorflow.org/tfx/guide/serving
- Original cover image: Sidecar racers — Helmut Fath & Wolfgang Kalauch. I edited the image to picture Google Pub/Sub service and tensorflow logos as sidecar riders to illustrate this sidecar pattern