Deploy your machine learning models with tensorflow serving and kubernetes
8 min read
Machine Learning, serving, architecture
Deploy your machine learning models with tensorflow serving and kubernetes
Machine learning applications are booming and yet there is not a lot of tools available for Data
Engineers to integrate those powerful models in production systems. Here I discuss how TensorFlow
Serving can help you accelerate delivering models in production.
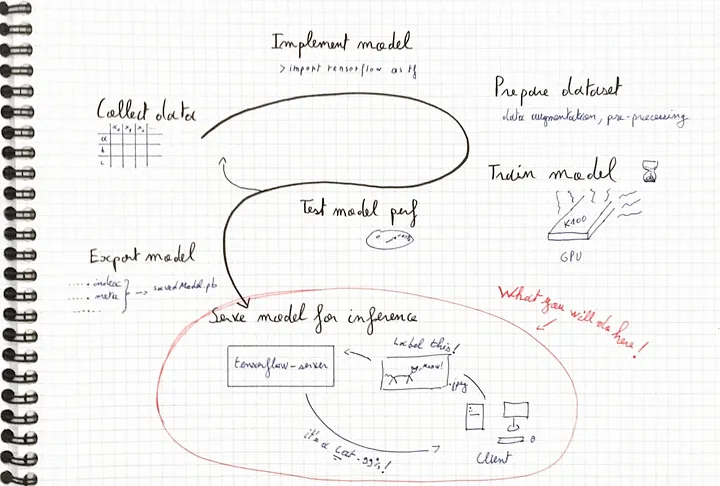
Serving is how you apply an ML model after you’ve trained it
Figure 1: Summary of a machine learning pipeline — here we focus on
serving the model
TensorFlow Serving in a nutshell
Tensorflow serving enables you to seamlessly serve your machine learning models.
Deploy a new version of your model and let TensorFlow Serving gracefully finish current
requests while starting to serve new requests with the new model.
Separate concerns, data scientists can focus on building great models while Ops can focus on
building highly resilient and scalable architectures that can serve those models.
Part 1 — Warm up: Set up a local TensorFlow server
Before going online it’s good to make sure your server works on local. I’m giving the big steps
here, find more documentation in the project readme.
git clone https://github.com/fpaupier/tensorflow-serving_sidecar, create a python3.6.5
virtual env and install the requirements.txt
Get TensorFlow Serving docker image: docker pull tensorflow/serving
Go to the model directory and rename the saved model subdirectory with a
version number,
since we are doing a v1 here let’s call it 00001 (it has to be figures). We do this because
TensorFlow Serving docker image search for folders named with that convention when searching
for a model to serve.
Now run the TensorFlow server:
bash
# From tensorflow-serving_sidecar/
docker run -t --rm -p 8501:8501 \
-v "$(pwd)/data/faster_rcnn_resnet101_coco_2018_01_28:/models/faster_rcnn_resnet" \
-e MODEL_NAME=faster_rcnn_resnet \
tensorflow/serving &
Just a note before going further:
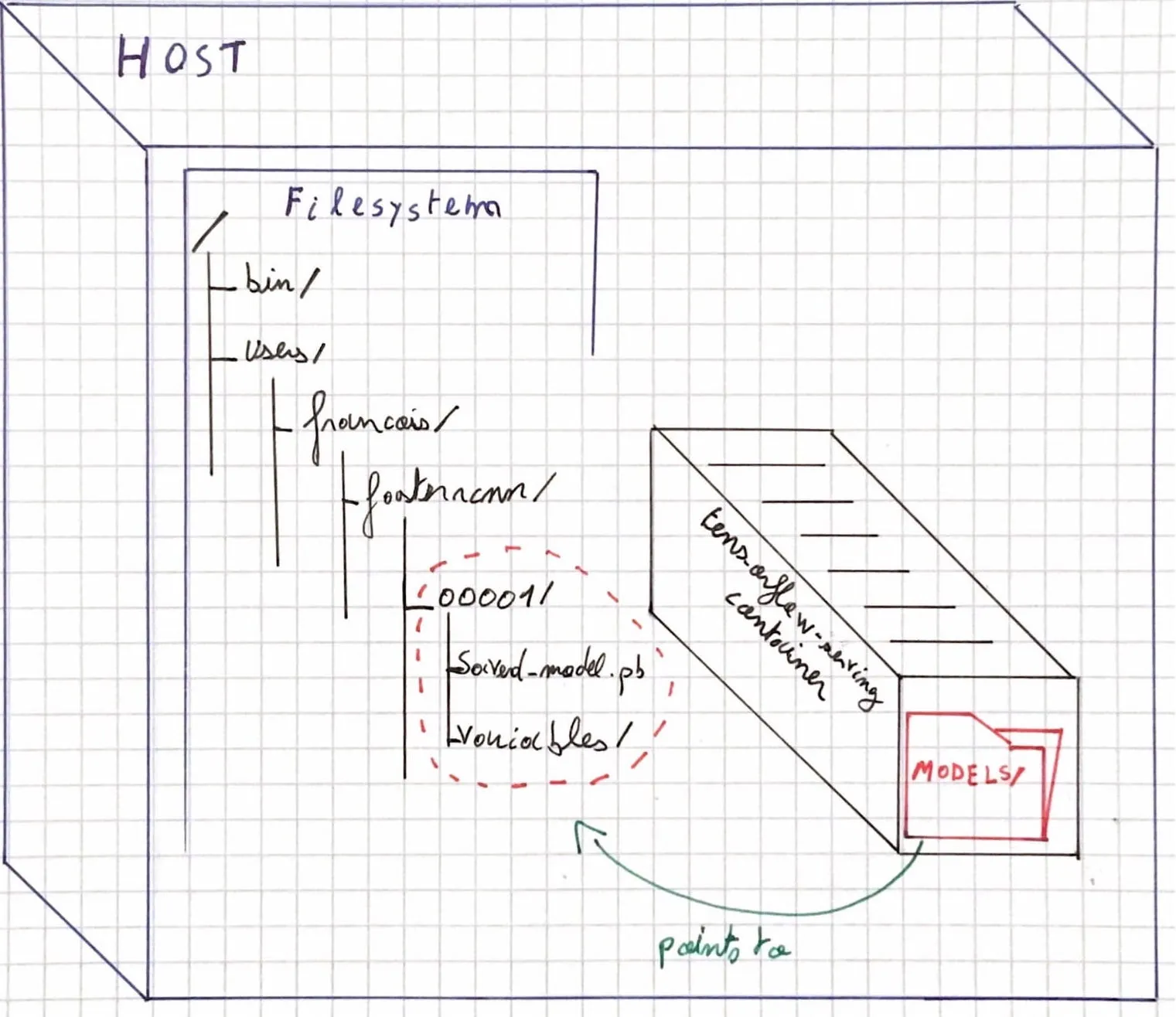
Figure 2: docker -v arg in our use case
Here we bind the port of the container and the localhost. Thus when we will call for inference
on localhost:8501 we will actually call the tensorflow server.
You also notice we link our localhost directory
faster_rcnn_resnet101_coco_2018_01_28 — where
the model is stored — with the container /models/faster_rcnn_resnet path.
Just keep in mind that at this point the savedModel.pb is solely on your machine,
not in the
container.
6. Perform the client call:
bash
# Don't forget to activate your python3.6.5 venv
# From tensorflow-serving_sidecar/
python client.py --server_url "http://localhost:8501/v1/models/faster_rcnn_resnet:predict" \
--image_path "$(pwd)/object_detection/test_images/image1.jpg" \
--output_json "$(pwd)/object_detection/test_images/out_image1.json" \
--save_output_image "True" \
--label_map "$(pwd)/data/labels.pbtxt"
Go check the path specified by --output_json and enjoy the result. (json and jpeg
output available)
Figure 3: expected inference with our object detection model
Great, now that our model works well, let’s deploy it on the cloud.
Part 2 — Serve your machine learning application on a Kubernetes cluster with TensorFlow
Serving
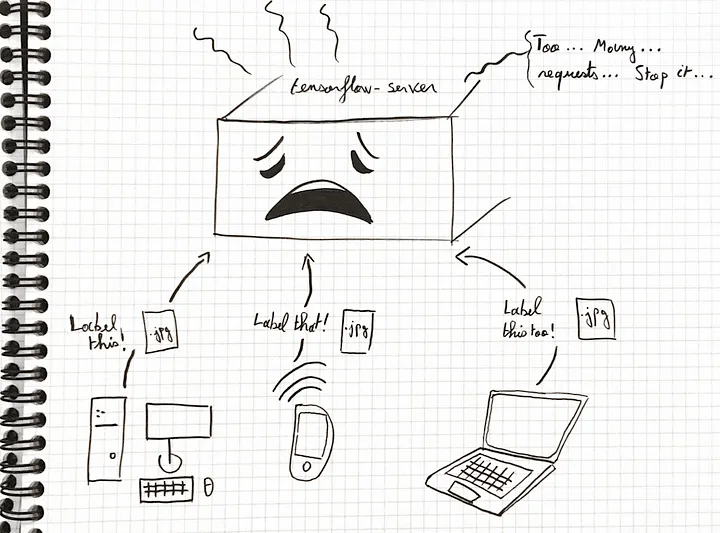
In a production setting, you want to be able to scale as the load is increasing on your app. You
don’t want your server to be overwhelmed.
Figure 4: An exhausted TensorFlow server directly exposed over the
network
To avoid this issue, you will use a kubernetes cluster to serve your tensorflow-server app. Main
improvements to expect:
The load will be balanced among your replicas without you having to think about it.
Do you want to deploy a new model with no downtime? No problem, kubernetes got your back.
Perform a rolling update to progressively serve your new model while gracefully terminating
the current requests on the former model.
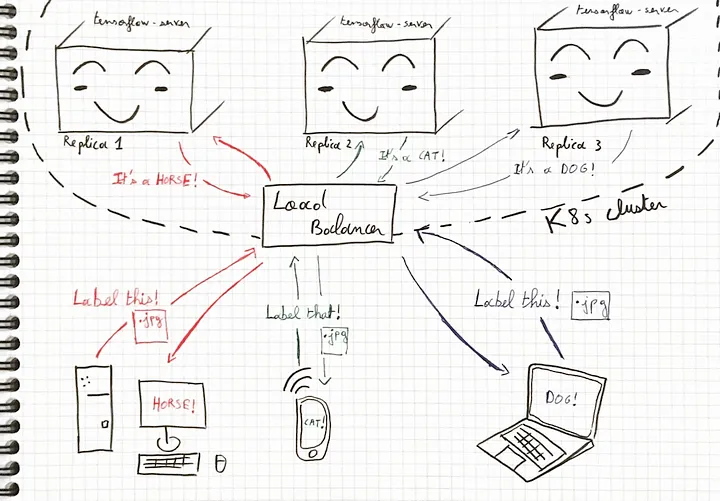
Figure 5: A tensorflow server application running on many replicas
in a k8s cluster, ensuring high availability to users
Let's dive in
First, we want to create a complete docker image with the object detection model embedded. Once
this is done, we will deploy it on a kubernetes cluster. I run my example on Google Cloud
Platform because the free tier makes it possible to run this tutorial for free. To help you
set
up your cloud environment at GCP you can check my tutorial
here.
Create a custom tensorflow-serving docker image
Run a serving image as a daemon: docker run -d --name serving_base
tensorflow/serving
Copy the faster_rcnn_resnet101_coco model data to the container's
models/ folder:
bash
# From tensorflow-serving_sidecar/
docker cp $(pwd)/data/faster_rcnn_resnet101_coco_2018_01_28 serving_base:/models/faster_rcnn_resnet
Commit the container to serve the faster_rcnn_resnet model:
Note: if you use a different model, change faster_rcnn_resnet in the
--change argument
accordingly.
faster_rcnn_resnet_serving will be our new serving image. You can check
this by
running docker
images, you should see a new docker image:
Figure 6: docker images result after creating a custom
tensorflow-serving image
Stop the serving base container
bash
docker kill serving_base
docker rm serving_base
Great, the next step is to test our brand-new faster_rcnn_resnet_serving image.
Test the custom server
Before deploying our app on Kubernetes, let’s make sure it works correctly.
Start the server: docker run -p 8501:8501 -t faster_rcnn_resnet_serving &
Note: Make sure you have stopped (docker stop CONTAINER_NAME) the previously running server
otherwise the port 8501 may be locked.
We can use the same client code to call the server:
We can check we have the same result. Let’s run this on a Kubernetes cluster now.
Deploy our app on Kubernetes
Unless you already have run a project on GCP, I advise you to check the Google
Cloud setup
steps.
I assume you have created and logged in a gcloud project named
tensorflow-serving.
You will use
the
container image faster_rcnn_resnet_serving built previously to deploy a serving
cluster with
Kubernetes in the Google Cloud Platform.
Login to your project: first list the available projects with gcloud projects
list,
select the PROJECT_ID of your project and run:
bash
# Get the PROJECT_ID, not the name
gcloud projects list
# Set the project with the right PROJECT_ID, i.e. for me it is tensorflow-serving-229609
gcloud config set project tensorflow-serving-229609
gcloud auth login
Create a container cluster:
First, we create a Google Kubernetes
Engine cluster for service deployment. Due to the
free trial
limitation, you cannot do more than 2 nodes here, you can either upgrade or go with the
two
nodes
which will be good enough for our use case. (You are limited to a quota of 8 CPUs in
your free
trial.)
You may update the zone arg, you can choose among e.g: europe-west1, asia-east1 - You
check all
the
zones available with gcloud compute zones list. You should see tomething
like that:
Figure 7: kubernetes cluster creation output
Set the default cluster for gcloud container command and pass cluster credentials to
kubectl:
bash
# Set the default cluster
gcloud config set container/cluster faster-rcnn-serving-cluster
# Pass cluster credentials to kubectl
gcloud container clusters get-credentials faster-rcnn-serving-cluster \
--zone 'us-east1'
Upload the custom tensorflow-serving docker image we built previously:
Let’s push our image to the Google
Container Registry so that we can run it on Google
Cloud
Platform. Tag the faster_rcnn_resnet_serving image using the Container
Registry format
and our project id, change the tensorflow-serving-229609 with your PROJECT_ID.
Also
change the tag at the end, here it's our first version, so I set the tag to
v0.1.0.
bash
docker tag faster_rcnn_resnet_serving gcr.io/tensorflow-serving-229609/faster_rcnn_resnet_serving:v0.1.0
If you run docker images, you now see an additional
gcr.io/tensorflow-serving-229609/faster_rcnn_resnet_serving:v0.1.0 image.
This gcr.io prefix allows us to push the image directly to the Container registry,
bash
# To do only once
gcloud auth configure-docker
docker push gcr.io/tensorflow-serving-229609/faster_rcnn_resnet_serving:v0.1.0
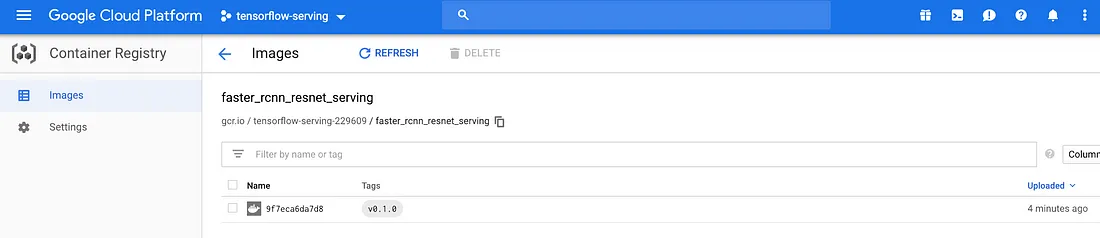
You have successfully pushed your image on GCP Container Registry, you can check it online:
Figure 8: docker image successfully pushed on Google
Container Registry
Using a single replica does not really make sense. I just do so to pass within the free
tier. Load balancing if you have only one instance to direct your query on is useless.
In a production setup, use multiple replicas.
We create them using the example Kubernetes config
faster_rcnn_resnet_k8s.yaml.
You
simply need to update the docker image to use in the file, replace the line image:
<YOUR_FULL_IMAGE_NAME_HERE>
with your actual image full name:
bash
# Update the image in faster_rcnn_resnet_k8s.yaml
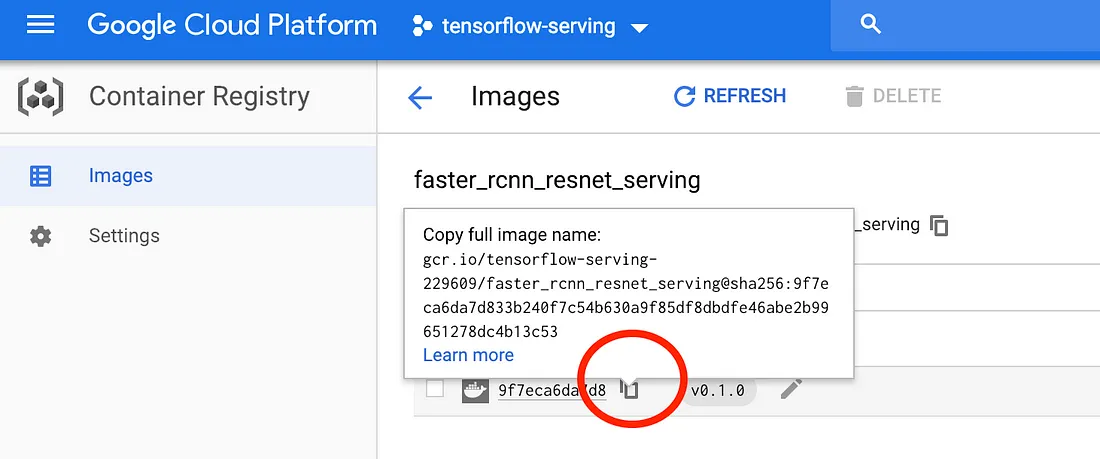
image: gcr.io/tensorflow-serving-229609/faster_rcnn_resnet_serving@sha256:9f7eca6da7d833b240f7c54b630a9f85df8dbdfe46abe2b99651278dc4b13c53
You can find it in your container registry:
Figure 9: find your docker full image name on google
container registry
And then run the following command
bash
# Run the following command from tensorflow-serving_sidecar/
kubectl create -f faster_rcnn_resnet_k8s.yaml
To check the status of the deployment and pods use the kubectl get
deployments for
the
whole deployment, kubectl get pods to monitor each replica of your
deployment, and
kubectl get services for the service.
Figure 10: Sanity check for deployment
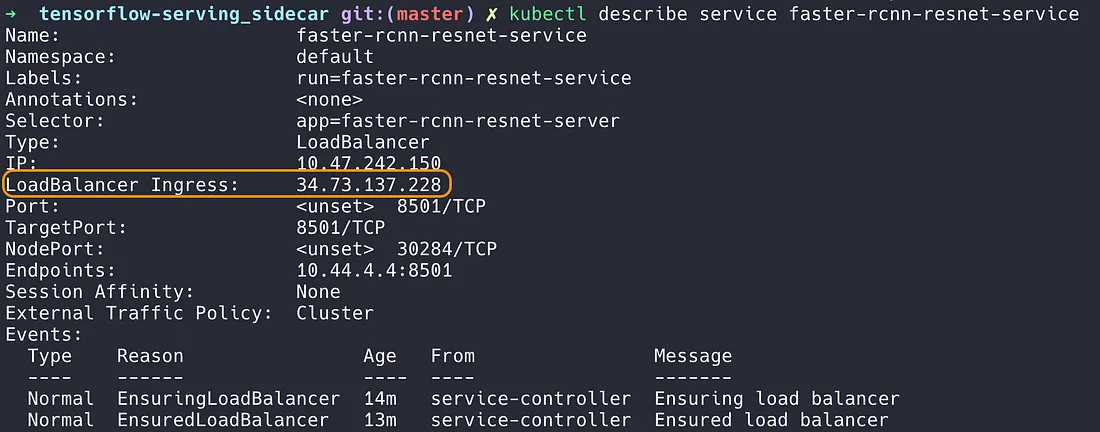
It can take a while for everything to be up and running. The service external IP address
is
listed
next to LoadBalancer Ingress. You can check it with the kubectl describe
service
command:
bash
# Describe the service
kubectl describe service faster-rcnn-resnet-service
Figure 11: Find the IP address to query upon to perform
inference
Query your online model:
And finally, let’s test this. We can use the same client
code. Simply replace the previously used
localhost in the --server-url arg with the IP address of the LoadBalancer Ingress
as
specified above.
Tensorflow serving offers a great basis on which you can rely to quickly deploy your model in
production with very little overhead.
Containerization of machine learning applications for their deployment
enables to separate the concerns between Ops and Data Scientists.
Container orchestration solutions such as Kubernetes combined with TensorFlow
Serving offer the possibility to deploy high availability models in minutes even
for people not familiar with distributed computing.
References
Tensorflow serving explained by Noah Fiedel, Software Engineer at Google who worked on Tensorflow Serving. It gives insights on how it has been built and for which purposes
https://www.youtube.com/watch?v=q_IkJcPyNl0